| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- SSM
- Bidirectional Associative Memory
- 삼성전자 소프트웨어멤버십 SSM
- 가상화
- BAM
- Friendship
- 고려대학교
- hopfield network
- 빅데이터
- Python
- 하이퍼바이저
- 패턴 인식
- NarwalFreo
- 파이썬
- 삼성
- 멤버십
- 갤럭시탭S8울트라
- 나르왈프레오
- 신경망
- 패턴인식
- 신경회로망
- 증강현실
- 물걸레로봇청소기추천
- 물걸레자동세척로봇청소기
- Google App Engine
- 인공지능
- 삼성소프트웨어멤버십
- 동아리
- Neural Network
- 구글 앱 엔진
- Today
- Total
정보공간_1
[7기 신촌 박진상] 기계학습 #5 - SVM의 이해와 LibSVM을 이용한 예측기 만들기 본문
[7기 신촌 박진상] 기계학습 #5 - SVM의 이해와 LibSVM을 이용한 예측기 만들기
알 수 없는 사용자 2015. 6. 26. 10:31안녕하세요 엘리트 7기 신촌 멤버십의 박진상입니다.
마지막 포스팅으로는 SVM에 대한 설명과 LibSVM을 이용해 기본적인 선형 분류 및 예측을 할 수 있는 시스템을 만들어보겠습니다.
SVM이란 Support Vector Machine의 약자로 지도학습을 위해 사용하는 학습 모델입니다. 분류와 예측에 주로 쓰이고, 너무나도 유명한 신경망 모델과 함께 가장 잘 알려진 학습 모델이기도 하죠. SVM은 지도학습을 위해 신경망과는 조금 다른 방법을 사용합니다. 설명을 돕기 위해 예를 들겠습니다. 다음과 같은 데이터 분포가 있다고 가정합시다. 물론 데이터는 feature값을 이용해 평면에 사영(Projection)했다고 하겠습니다.

이번에는 검은색으로 칠해진 데이터가 들어왔다고 해보겠습니다. 검은색은 아직 이 데이터가 분류되지 않았음을 의미합니다. 이 데이터는 빨강과 파랑 중 어느 색을 가져야 할까요? 우리는 ‘일반적으로’ 파란색으로 분류할 수 있을 것입니다. Feature를 나타낸 좌표 상에서 파란색에 더 가깝기 때문이죠. 즉, 우리는 이 검은색 데이터가 파란색 데이터와 더 ‘유사하다’고 분류(Classify)하고, 파란색이다 라고 예측(Predict)할 수 있습니다. 그렇다면 논란의 여지를 없애기 위해, 다음과 같이 빨강과 파랑 사이에 선을 긋고, 분류의 기준점으로 삼겠습니다.

이 때 이 초록색 기준이 되는 선을 SVM에서는 초평면(Hyperplain)이라고 합니다. 초평면의 결정은 초평면으로부터 각 파란색, 빨간색 데이터들간의 벡터 거리를 측정하여 데이터 점들간의 거리가 최대가 되는 평면이 결정되게 됩니다. 이러한 종류를 최대 마진 초평면(Maximum-margin hyperplain)이라 하며 가장 일반적인 형태입니다. 물론 설명을 위한 예시는 가장 단순한 2차원 형태의 선형 SVM을 얘기한 것입니다. 당연하게도 feature가 늘어남에 따라서 N 차원의 모델도 SVM으로 분류할 수 있습니다. 그 경우에는 초평면이 직선이 아닌 평면 및 그 이상의 형태를 띄게 되겠죠?
하지만 실데이터를 분류하는데 있어서 선형(Linear)으로 분류하는 것이 거의 불가능 하다는 건, 앞선 포스팅에서 몇차례 얘기했습니다. SVM은 이러한 점을 극복하기 위해 커널트릭(Kernel trick)이라는 것을 사용합니다. 커널 트릭을 이용한 비선형 SVM 모델 역시 초평면을 결정하는 기본 원리는 같습니다. 하지만, 평면 자체가 일그러지는 것이 아닌, 트릭을 이용해서, 각 데이터가 평면에 이르는 거리에 차이를 주는 방식입니다. 벡터 공간 안의 모든 데이터가 선형 분류에 쓰이는 내적 연산이 아닌, 비선형 커널 함수를 사용함으로써 고차원에서 데이터를 선형분류 관계에서 벗어나게 합니다. 이로 인해, 고차원에서도 SVM은 본질 그대로 여전히 선형성을 유지하겠지만, 기존 차원에서는 비선형으로 일그러진 초평면이 생기게 됩니다.

커널 함수의 원리와 비선형 SVM의 연구는 수학적으로 증명이 되었고, 이에 대한 전문적 수학자료는 커널트릭(Kernel trick)에 관한 논문을 참조하시면 좋을 듯 합니다.
그렇다면 SVM을 이용한 간단한 분류기(Classifier)를 만들어보겠습니다. 직접 SVM 커널부터 구조화하는 것보다는 잘 알려진 SVM 라이브러리인 LibSVM을 사용해서 실습을 해보겠습니다.
LibSVM은 5개의 언어(Java, C/C++, Python, C#)를 대상으로 지원합니다. 다운로드는 다음 사이트에서 받으실 수 있습니다.(https://github.com/cjlin1/libsvm) 본인이 Import하기 원하는 언어의 모듈을 다운받아 사용하시면 됩니다.
LibSVM을 이용한 실습이므로, 코어 코드를 보기보다는 프론트 레벨에서 어떻게 이용할 수 있는지를 설명하겠습니다. 깃허브에서 코드를 다운받아 사용하실 때 주의하실 게 있습니다. 가령 파이썬 모듈은 다음과 같이 2개의 파일로 구성되어 있습니다.

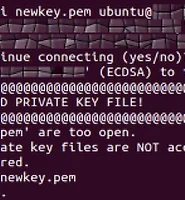
각 파일들(svm.py, svmutil.py) 내부를 보시면 ‘코어 엔진’ 코드는 존재하지 않습니다. LibSVM의 코어 엔진은 C로 만들어진 모듈을 사용하니, 설치할 때 윈도우 사용자의 경우에는 libsvm.dll 파일을 반드시 다운받아 설치해주셔야 합니다.
환경이 구축되었다면 사용은 간단합니다. 언어마다 모듈 사용에 있어서 조금씩 차이는 있지만 주요 루틴은 다음 4단계로 이루어집니다.
(1) 머신의 환경을 설정한다.
(2) 훈련 데이터셋 및 검증 데이터셋을 설정한다.
(3) 훈련 데이터셋을 이용해서 훈련한다.
(4) 예측값과 검증 데이터셋의 결과값을 비교해 오류를 산출한다.
위와 같은 루틴을 숙지하시고 실제 사용해주시면 됩니다. LibSVM에서 사용하는 입력 포멧을 살펴보고 바로 사용해보겠습니다.

LibSVM은 위와 같은 데이터 포멧을 사용합니다. 라벨은 binary값(두개의 분류값)이 사용됩니다. Feature는 1부터 인덱스 번호를 주어 feature의 개수대로 부여하시면 되겠습니다. 부여하는 만큼 차원은 늘어나겠죠? 저는 다음과 같은 훈련셋과 검증셋을 이용하겠습니다.

대략 2차원 평면에서 1사분면과 4사분면을 구분하게끔 간단한 분류 데이터를 훈련시키고 예측값을 테스트해보겠습니다.

예측 결과와 주어진 정답간의 오차까지 추출해내는 것을 볼 수 있습니다. 안타깝게도 오차가 발생을 했지만, 그래도 추이를 감안했을 때, 더 많은 일반적인 데이터가 주어진다면 정확도는 올라갈 것입니다.
이렇게 총 5번의 포스팅을 마치게 되었습니다. 다소 포스팅이 짧고 실습 위주를 보여드리고자 최근에 연구하는 딥러닝에 대해서는 다루지 못한게 좀 아쉽네요. 주로 기초에 대해 다뤘지만 포스팅을 보신 분들께 많은 도움이 되었으면 합니다. J

'IT 놀이터 > Elite Member Tech & Talk' 카테고리의 다른 글
| [7기 수원 박성진] EC2에서의 django 프로젝트 생성 및 외부 접근 설정 (0) | 2015.07.02 |
|---|---|
| [7기 수원 박성진] EC2 접속 후 django 설치 (0) | 2015.07.02 |
| [7기 강남 이학경 ] Cortex-M# (STM32F#)전체 환경 셋팅 (0) | 2015.06.08 |
| [7기 강남 이학경] Bluetooth 4.x 버전 및 전력 효율 분석 (0) | 2015.06.08 |
| [7기 대구 유용수] IO Completion Port 4장. IOCP구조체와 함수, 실습 (0) | 2015.05.25 |