| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 구글 앱 엔진
- 증강현실
- 가상화
- 신경회로망
- 나르왈프레오
- Neural Network
- 물걸레로봇청소기추천
- 고려대학교
- 멤버십
- 삼성전자 소프트웨어멤버십 SSM
- NarwalFreo
- 인공지능
- SSM
- 삼성소프트웨어멤버십
- BAM
- 갤럭시탭S8울트라
- 패턴인식
- 물걸레자동세척로봇청소기
- hopfield network
- Bidirectional Associative Memory
- 삼성
- Google App Engine
- 동아리
- Friendship
- Python
- 신경망
- 빅데이터
- 하이퍼바이저
- 파이썬
- 패턴 인식
- Today
- Total
정보공간_1
[7기 신촌 박진상] 기계학습 #2 - 파라미터 조정에 의한 학습 본문
안녕하세요. 엘리트 7기 신촌 멤버십의 박진상입니다.
지난 시간에는 기계학습의 한 종류인 지도학습이란 무엇인가에 대해 이론적인 부분을 배워보았습니다. 이번 시간에는 배운 이론을 바탕으로 가장 간단한 형태의 지도학습인 파라미터 조정을 통한 기계학습을 실습해보겠습니다.
파라미터 조정에 의한 학습법은 데이터를 수치화하고, 모델을 수식화합니다. 즉 학습에 의해 수식화된 모델을 얻는 것을 목표로 합니다. 실습을 통해 배워보도록 하겠습니다.
데이터 마이닝을 통해 다음과 같은 데이터를 얻었다고 해보겠습니다.

위와 같은 종류의 데이터가 주어졌을 때, 앞으로 나올 데이터를 예측할 수 있을까요? 지금은 좌표 위에 점이 4개 밖에 없지만, 다음 그림과 같이 데이터가 많이 있을 경우, 우리는 다음에 데이터가 기록된다면, 그 점은 왼쪽 아래에서 오른쪽 위로 향하는 직선 경로 상에 있을 것이라고 예측할 수 있게됩니다.

물론 아닐 수도 있지만, 예측을 했을 때 예측이 ‘어느 정도’ 맞는다면, 시스템의 신뢰도는 ‘어느 정도’ 보장을 할 수 있게 됩니다. 이런 종류의 수치 데이터로부터 수치를 설명할 수 있는 수식을 결정하는 것을 회귀분석이라고 합니다. 그리고 예시와 같이 단순 직선형의 회귀분석을 선형회귀 라고 말합니다. 회귀 분석으로는 예시처럼 단순한 선형 뿐 아니라 비선형 고차원의 데이터 들에 대해서도 다루게 됩니다. 하지만 예제에서는 단순한 선형회귀를 통해 학습법을 배워보도록 하겠습니다.
데이터에 대한 모델을 선형(Linear)으로 잡고 있기 때문에 우리는 다음과 같은 수식을 유추할 것입니다.

위의 식의 값을 통해 수치 데이터들을 설명해야 합니다. 반듯한 직선인 위의 선형 방정식으로 수치를 설명하기에는 오차가 있기 때문에 학습 데이터를 정확히 계산할 수는 없습니다. 하지만 학습을 통해 오차를 최소화 하는 방향으로 로직을 구현해야 합니다. 수치데이터를 분석하여 수식을 완성하기 위한 분석법에는 여러 가지가 있는데, 그 중 대표적인 방법은 최소제곱법(Least Squares Method) 이라 불리는 방법입니다. 이 방법은 오차 S를 직선 y = a0 + a1x 라는 식으로 부터의 거리 합으로 해서 그 값을 최소가 되게, 즉, 예측한 직선에서 데이터가 가장 벗어나지 않는 방향으로 계수를 결정합니다.

이 후에는 수학적인 정리가 조금 들어가는데요. 다소 복잡하니 간략하게 넘어가겠습니다… 계수 a0와 기울기 a1을 구하기 위해 계수로 편미분하고 각 값을 0으로 두어 다음과 같은 식을 유도해냅니다. N은 데이터의 숫자를 의미합니다.


위의 식은 데이터가 일차형이라고 가정했을 때 유도된 식이며, 실제 모델이 고차함수나 대수함수인 경우에도 같은 방법으로 유도하여 이용할 수 있습니다.
식이 유도되었다면 코드로 옮기는 것은 간단합니다. 입력받은 x, y 좌표에 대해 위의 식을 적용해주면 되는 것이죠. 다만 식에서 보는 것과 같이 모든 데이터들의 값을 합산해야 합니다.

저는 테스트의 용이성을 위해서 명령어 인수를 통해서 파일로부터 데이터를 입력받을 수 있게끔 했습니다. 그럼 데이터를 입력해서 결과를 확인해볼까요?

4개의 점 입력에 대해 위와 같은 직선이 유추되었습니다. 이 직선의 그래프는 다음과 같습니다.

점을 더 입력을 해보겠습니다.

점들이 좀 더 낮은 y 값을 가짐에 따라서 직선이 이전보다 낮게 유추가 되는 것을 볼 수 있습니다. 그래프로는 다음과 같이 표현됩니다.

이제 처음 직선보다 좀 더 많은 데이터를 설명할 수 있는 그래프가 되었습니다. 실습은 기초였지만, 방금 선형 회귀법으로 빅데이터라고 부를 수 있을 만한 많은 데이터가 주어진다면 학습된 머신은 의미있는 선형 예측 결과를 도출해낼 수도 있습니다. 물론 비즈니스 모델은 단순히 선형으로 분석 안되는 경우가 많으며 이런 경우에는 여러가지 방법을 많이 도입을 해야합니다. 그리고 그러한 복잡한 모델들은 단순한 선형에 비해 많은 이슈를 마주치게 됩니다. :-)
다음 포스팅에는 텍스트 마이닝의 기초 분석법 들에 대해 얘기하겠습니다.

'IT 놀이터 > Elite Member Tech & Talk' 카테고리의 다른 글
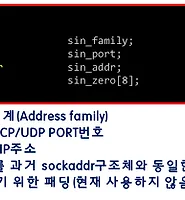
| [7기 대구 유용수] IO Completion Port 2장.WinSock 이해하기 (0) | 2015.04.14 |
|---|---|
| [7기 강남 이학경] 2장 : STM32CubeMX 프로젝트 생성 방법 (0) | 2015.04.09 |
| [7기 강북 전소현] 안드로이드 오디오 스트림 타입 (0) | 2015.04.02 |
| [7기 수원 박성진] 아마존 웹 서비스 EC2 시작하기 (1) | 2015.04.01 |
| [7기 강남 이학경] 1장 : STM32CubeMX의 개념과 설치방법 (0) | 2015.03.25 |